


Web scraping to proces pozyskiwania danych z różnych stron internetowych poprzez automatyczne pobieranie i analizę zawartości. Jest to technika, która umożliwia wydobycie informacji z witryn internetowych bez konieczności interakcji użytkownika. Web scraping jest wykorzystywany w różnych dziedzinach, takich jak analiza rynku, monitorowanie cen, zbieranie danych do badań naukowych czy tworzenie spersonalizowanych usług internetowych. Jednakże, pomimo swojego potencjału, może budzić kontrowersje związane z prywatnością i etyką, zwłaszcza gdy dane są pobierane bez zgody właściciela strony. Warto zrozumieć zarówno korzyści, jak i wyzwania związane z web scrapingiem, aby skutecznie korzystać z tej technologii, przestrzegając jednocześnie przepisów prawa.
Legalność web scrapingu
Jeśli chodzi o ochronę danych osobowych, przepisy RODO w Unii Europejskiej określają, w jaki sposób dane osobowe mogą być zbierane, przechowywane i przetwarzane. Web scraping może naruszać te przepisy, zwłaszcza jeśli dane osobowe są pozyskiwane i wykorzystywane bez odpowiednich uprawnień.
Dlatego ważne jest, aby zawsze sprawdzać przepisy i przestrzegać polityk witryn internetowych. Niektóre strony mogą mieć wyraźne zapisy zabraniające web scrapingu, których złamanie może skutkować konsekwencjami prawnymi. Warto również podkreślić, że niektóre formy web scrapingu, zwłaszcza te, które prowadzą do nadmiernego obciążenia serwerów, mogą naruszać zasady fair use i być uznawane za nielegalne.
Działania ograniczać mogą także zabezpieczenia stron, takie jak captcha czy blokady IP, które utrudniają lub blokują dostęp botom web scrapingowym. Strony internetowe, które są dynamicznie ładowane za pomocą JavaScript, mogą wymagać bardziej zaawansowanych narzędzi (np. Selenium) do poprawnego web scrapingu. Warto też pamiętać, że zmienność struktury strony i ewentualne błędy w kodzie web scrapingowym mogą prowadzić do nieprawidłowych wyników i błędnych interpretacji danych.

Do czego przydaje się web scraping
- Dostęp do danych dostępnych publicznie na stronach internetowych jest cenny dla analizy rynkowej, monitorowania konkurencji czy pozyskiwania informacji do badań.
- Automatyzacja procesów zbierania danych pozwala zaoszczędzić czas i nakłady pracy w porównaniu do manualnego zbierania informacji z wielu źródeł.
- Dzięki zbieraniu danych z różnych źródeł można analizować trendy i preferencje użytkowników, co jest przydatne w podejmowaniu decyzji biznesowych.
- Web scraping może być wykorzystywany do personalizacji treści dostarczanych użytkownikom, co z kolei zwiększa zaangażowanie.
- Zbieranie danych z mediów społecznościowych, forów czy recenzji może dostarczać informacje na temat opinii klientów na temat produktów i usług.
- Web scraping pozwala na monitorowanie cen konkurencyjnych produktów i usług. Analiza tych danych może pomóc w dostosowywaniu własnych cen, tworzeniu atrakcyjnych ofert i zrozumieniu, jak cena wpływa na pozycję rynkową.
- Monitorowanie dostępności produktów u konkurencji pozwala na szybkie reagowanie na ewentualne braki w asortymencie lub problemy z dostawą. To może pomóc w utrzymaniu stałej dostępności produktów dla klientów.
- Dzięki monitorowaniu treści reklamowych, kampanii promocyjnych i działań marketingowych konkurentów można uzyskać wgląd w ich strategie promocyjne. To pomaga w projektowaniu własnych działań marketingowych, aby lepiej konkurować na rynku.
- Web scraping pozwala na śledzenie zmian w ofercie produktowej konkurencji, w tym nowych produktów i usług czy aktualizacji istniejących. To może być istotne dla dostosowania własnej oferty do oczekiwań klientów.
- Web scraping umożliwia przeanalizowanie struktury strony internetowej, co może być przydatne w analizie doświadczenia użytkownika, nawigacji i ogólnego projektu witryny. To ważne, aby dostosować własną stronę do oczekiwań klientów.

Popularne narzędzia do web scrapingu
Istnieje szereg narzędzi ułatwiających ten proces. Jednym z popularnych narzędzi do web scrapingu jest BeautifulSoup. To biblioteka w języku Python, która umożliwia łatwe przeszukiwanie struktury HTML i XML, ułatwiając wyciąganie konkretnych danych.
Innym powszechnie używanym narzędziem jest Scrapy, również napisane w języku Python. To framework, który umożliwia programistom tworzenie zaawansowanych i skalowalnych skryptów do web scrapingu. Ma wiele wbudowanych funkcji ułatwiających nawigację po stronach i ekstrakcję danych.
Do popularnych narzędzi należy również Selenium, które jest często stosowane w automatyzacji testów aplikacji internetowych, ale może być także używane do web scrapingu. Selenium pozwala na interaktywne przeglądanie stron internetowych, symulując działania użytkownika, co jest przydatne, gdy dane są generowane dynamicznie przez skrypty JavaScript.
Nie można również pominąć narzędzi w chmurze, takich jak Octoparse czy ParseHub. Są to platformy, które oferują interfejsy graficzne do tworzenia reguł scrapingu bez konieczności programowania. Ułatwiają one web scraping osobom, które nie są programistami, ale chcą korzystać z możliwości tej technologii.
Przykłady kodu w Pythonie
Python jest jednym z najpopularniejszych języków programowania do web scrapingu ze względu na swoją czytelność, elastyczność i bogatą bazę bibliotek wspierających ten proces. Poniżej przedstawię przykładowe kody, które są stosowane w scrapowaniu stron.
Przykład 1: Pobieranie danych statystycznych
Możesz użyć Pythona do pobierania danych statystycznych ze stron internetowych, takich jak ceny produktów, oceny, liczba dostępnych produktów itp.

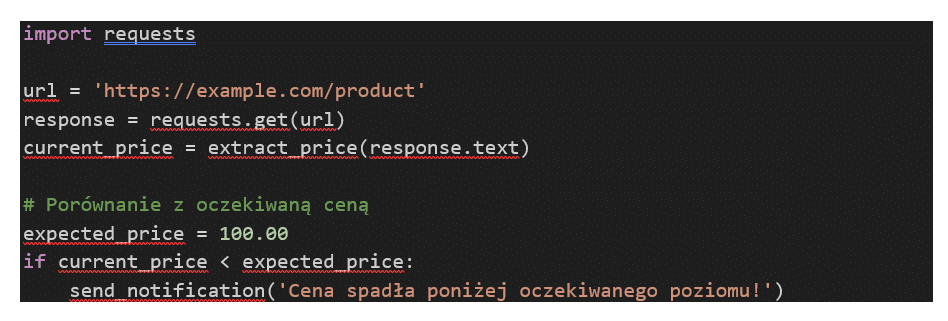
Przykład 2: Monitorowanie cen
Webscraping może być używany do monitorowania cen produktów na różnych stronach internetowych. Możesz dostosować swój skrypt do automatycznego sprawdzania cen i otrzymywania powiadomień, gdy cena spada poniżej określonego poziomu.
Przykład 3: Analiza treści
Python może być używany do analizy treści na stronach internetowych, takich jak artykuły, recenzje czy komentarze. Można stosować różne biblioteki, takie jak Natural Language Toolkit (NLTK), do analizy tekstu.

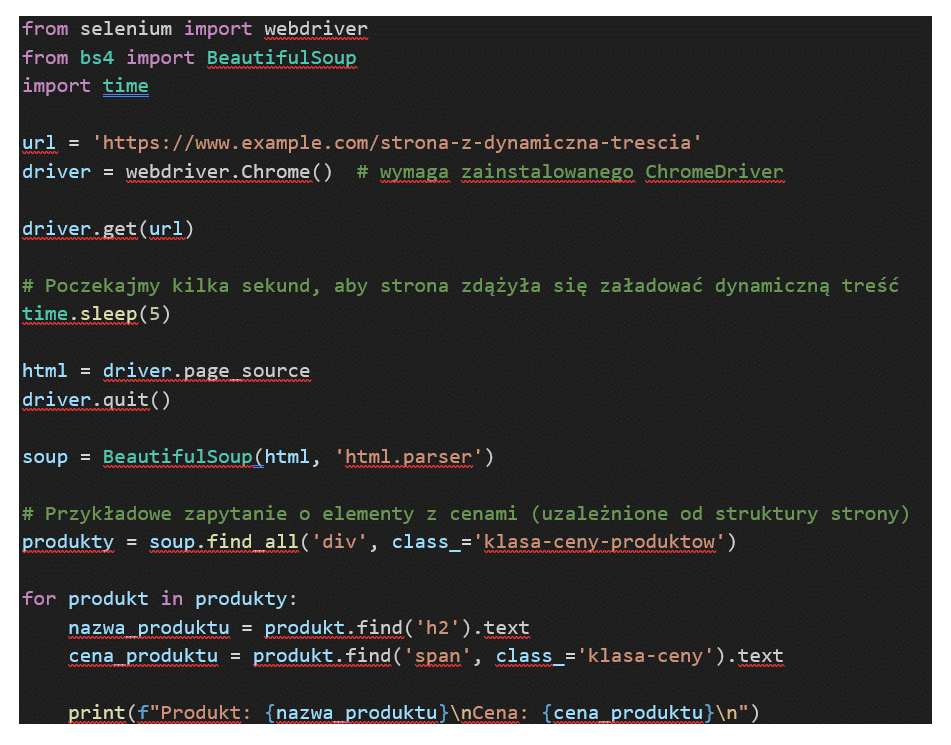
Przykład 4: Pobieranie danych ze strony z dynamicznym ładowaniem treści (z użyciem Selenium)
Kod używa bibliotek Selenium i BeautifulSoup w języku Python do automatycznego przeglądania strony internetowej z dynamiczną treścią, a następnie analizuje i wydobywa pewne informacje ze strony.

Wypełnij formularz
Przygotujemy dla Ciebie bezpłatną wycenę!
Dodatkowo otrzymasz bezpłatnie dostęp do kursów z marketingu internetowego.








