

Czym są linki kanoniczne
Powtarzająca się treść, określana w SEO jako duplicate content, to jeden z tych elementów, które skutecznie utrudniają uzyskanie wysokiej pozycji w wynikach wyszukiwania. Co jednak w sytuacji, gdy struktura Twojego serwisu powoduje, że do tej samej zawartości kieruje kilka różnych adresów? Jedną ze skutecznych metod pozwalających na uniknięcie duplikacji wewnętrznej jest dodanie do strony atrybutu rel canonical, informującego wyszukiwarkę o tym, która wersja URL jest tą „właściwą”. Sprawdź, co to jest link kanoniczny, po co się go stosuje i jak poprawnie wdrożyć tag canonical na swojej stronie internetowej.
Określeń na omawiany w tym tekście atrybut jest wiele. W branżowych artykułach, na blogach SEO oraz w wytycznych dla webmasterów możesz spotkać się z takimi terminami jak:
- link kanoniczny,
- canonical URL,
- rel=canonical,
- canonical URL tag,
- tag kanoniczny,
oraz paroma innymi, np. canonical links. Wszystkie dotyczą tego samego tagu umieszczanego w nagłówku strony internetowej lub jej poszczególnych podstron. Wszystko po to, by poinformować wyszukiwarki o tym, który adres URL jest oryginalny (kanoniczny) i który powinien zostać zaindeksowany przez roboty.
Przykład: wyobraź sobie, że do podstrony „Oferta” w Twoim serwisie prowadzi kilka różnych adresów URL, np.:
- http://twojastrona.pl/oferta (adres główny podstrony),
- http://www.twojastrona.pl/oferta (podstrona w subdomenie www),
- http://twojastrona.pl/oferta/print (wersja podstrony do druku).
Brak tagu canonical URL sprawi, że Googlebot będzie musiał samodzielnie wybrać wersję kanoniczną strony, a to może doprowadzić występowania zjawiska kanibalizacji w wynikach wyszukiwania, którą powoduje właśnie niepożądane zjawisko duplicate content.
Jak sprawdzić, czy strona posiada zaimplementowany tag canonical
Aby dowiedzieć się, czy do strony dodany został tag rel=canonical, możesz szybko sprawdzić zawartość sekcji head w kodzie HTML strony. Użyj kombinacji klawiszy Ctrl+U lub skorzystaj z narzędzi SEO, np. Google Search Console (narzędzie do sprawdzania adresu URL) czy gotowej wtyczki do przeglądarki np. SEO META in 1 CLICK.
Canonical URLs a SEO
Z punktu widzenia pozycjonowania Twojego serwisu www, linki kanoniczne pełnią istotną funkcję. Przede wszystkim ich wdrożenie zapobiega duplikacjom contentu, gdyż roboty Google różne URL-e traktują jako całkowicie inne strony www. Zwracamy również uwagę na to, że zastosowanie canonical links pozwala przekazywać stronie oryginalnej moc SEO od stron niekanonicznych. Jeśli Twoja witryny www ma rozbudowaną strukturę i składa się z wielu unikalnych, indeksowanych podstron, canonical URLs pomogą Ci również optymalizować dedykowany budżet indeksowania (ang. crawl budget).
Jak wdrożyć rel canonical na stronie www
Link rel=canonical możesz wdrożyć na dwa sposoby – korzystając z sekcji head w kodzie strony lub z nagłówka HTTP dla zasobów nie-HTML-owych.
Link rel=canonical w sekcji head
Ten sposób jest najbardziej oczywisty, dlatego z tej metody najchętniej korzystają specjaliści SEO:

Korzystając z popularnych CMS-ów, takich jak WordPress, Joomla czy PrestaShop, możesz ustawić tag rel canonical bez jakiejkolwiek samodzielnej ingerencji w kod HTML witryny – wystarczy, że skorzystasz z dedykowanej wtyczki, np. YoastSEO dla WordPressa.

Nagłówek http rel=canonical
W przypadku dokumentów innych niż HTML, np. PDF, DOC czy PPTX, nie ma możliwości edycji sekcji head. W takiej sytuacji najlepszym rozwiązaniem jest użycie nagłówka HTTP, który przyjmuje poniższą postać:
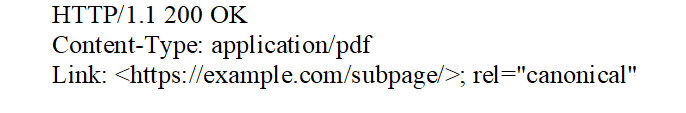
Jego implementacja jest możliwa przez edycję pliku .htaccess. Przykładowy kod:

Co jeszcze warto wiedzieć?
Pamiętaj jednak, że link rel canonical to dla Google jedynie sugestia, a nie wiążąca dyrektywa. Google może za sprawą swoich algorytmów heurystycznych w pewnych sytuacjach uznać za kanoniczny inny adres niż wskazany, a weryfikacja tego stanu jest możliwa w Google Search Console.
Canonical w przypadku błędnego wdrożenia może też wywołać spore problemy z indeksacją zawartości strony internetowej. Taki stan rzeczy może mieć miejsce na przykład po zmianie domeny, ale pozostawieniu starego odniesienia w tagu canonical.
Jeśli chcesz mieć sto procent pewności, że zduplikowane adresy zostały usunięte z indeksu do konsolidacji, wykorzystaj przekierowanie 301.










