


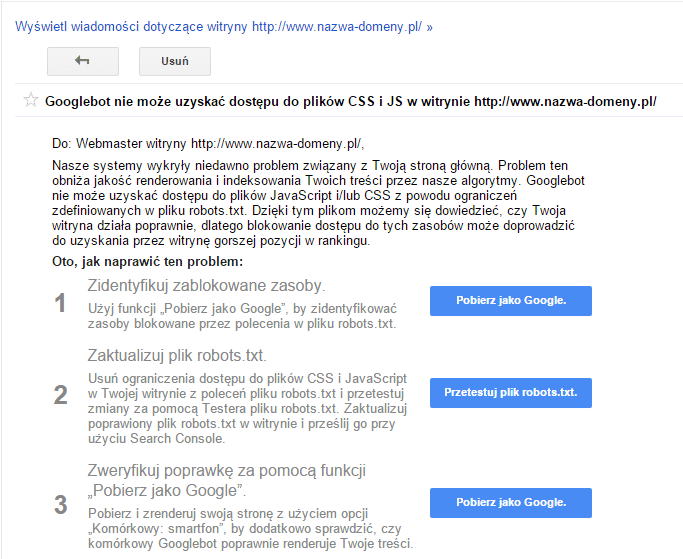
Od kilkunastu dni w Search Console (Google Webmaster Tools) można znaleźć nowe powiadomienie – „Googlebot nie może uzyskać dostępu do plików CSS i JS w witrynie http://xyz.pl/”. Spokojnie, to nic strasznego. W poniższym wpisie krok po kroku opiszę, jak naprawić ten problem.
Tytułem wstępu
Plik robots.txt zawiera reguły, które są interpretowane przez roboty indeksujące, w tym Googlebota (robot wyszukiwarki Google). Powinien on znajdować się w głównym katalogu strony i być dostępny pod adresem nazwa_domeny.pl/robots.txt.
W przypadku, kiedy dostęp do zasobu będzie zablokowany przez jedną z reguł w wyżej wymienionym pliku (dyrektywa Disallow), nasza strona może się renderować niepoprawnie. Błędne reguły blokujące zasoby mogą utrudniać indeksację i interpretację stron przez roboty wyszukiwarek, może to również wpłynąć negatywnie na pozycje.
Jeżeli otrzymałeś powiadomienie o problemie z dostępem do plików, prawdopodobnie w robots.txt zostały przypadkowo lub domyślnie zablokowane zasoby niezbędne do poprawnego renderowania strony przez roboty wyszukiwarek.
Renderowanie strony
Po zalogowaniu w narzędziu Search Console możemy sprawdzić, jak renderuje się nasza strona. Wybieramy zakładkę „Indeksowanie” i wybieramy opcję „Pobierz jako Google”. Następnie wpisujemy adres do podstrony i klikamy „Pobierz i zrenderuj”. Po kilku sekundach otrzymamy wynik. Jeżeli strona ma status „Częściowo ukończony” oznacza to, że występuje problem z jej zasobami – np. zostały zablokowane w pliku robots.txt lub nie są dostępne. Po kliknięciu wyświetli się porównanie wyglądu strony dla użytkownika i robota, a poniżej tabela z adresami do zasobów i przyczyną, z jakiej Googlebot nie uzyskał dostępu do zasobu.
Niestety strona, która posiada zablokowane zasoby, np. CSS, JPG czy JS, może wyglądać zupełnie inaczej. Dlatego bardzo ważne jest, żeby odblokować wszystkie niezbędne pliki.
Podpowiedzą może być wspominana już tabela. Adresy do zasobów należy odblokować w pliku robots.txt dyrektywą Allow. Jak to zrobić? Odpowiedź znajduje się poniżej.
Odblokowanie zasobów
Tak jak wspominałem wcześniej, do odblokowanie zasobów służy dyrektywa Allow. Należy pamiętać, żeby nie odblokować przypadkiem dostępu do plików, które nie powinny się indeksować.
Do problemu można podejść na kilka sposobów:
- Odblokować cały folder np. Allow: /thems/rwd – nie polecam tego sposobu, ponieważ Google może zaindeksować częściowe widoki kalendarza czy galerii – takie kwiatki niestety też można znaleźć w indeksie Google.
- Odblokować dokładnie określone zasoby – jest to akceptowany sposób, aczkolwiek może być uciążliwy dla serwisów, które posiadają ich bardzo dużo pod różnymi adresami, ponieważ po zrenderowaniu otrzymamy tylko część zasobów, które są zablokowane. Konieczne będzie kilkukrotne zgłoszenie strony do zrenderowania.
- Odblokowanie rozszerzeń plików w wybranych folderach – moim zdaniem jest to jeden z najlepszych sposobów. Za pomocą jednej reguły możemy np. odblokować wszystkie pliki CSS w folderze thems.
Reguły w pliku robots.txt
Załóżmy, że zawartość pliku robots.txt wygląda następująco
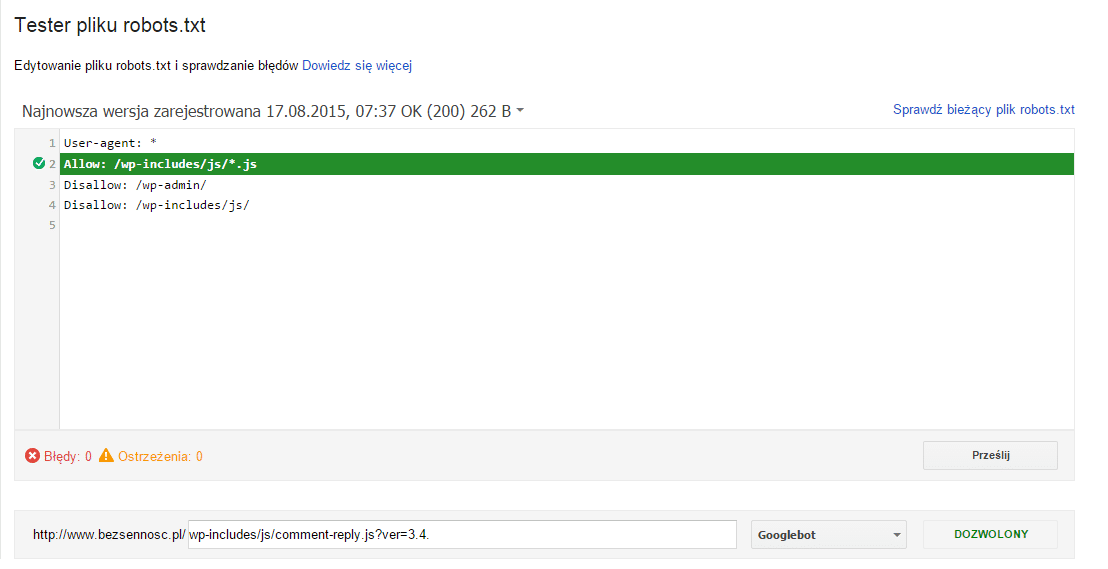
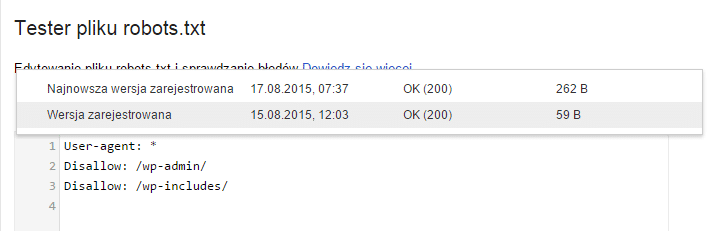
User-agent: * Disallow: /wp-admin/ Disallow: /wp-includes/
Żeby odblokować zasób o ścieżce /wp-includes/js/comment-reply.js?ver=3.4.1, należy dodać dyrektywę Allow: /wp-includes/js/*.js. Zawartość pliku robots.txt po zmianach znajduje się poniżej.
User-agent: * Allow: /wp-includes/js/*.js Disallow: /wp-admin/ Disallow: /wp-includes/
Oczywiście, jeżeli jesteśmy pewni, co do zawartości plików w danym katalogu, nic nie stoi na przeszkodzie, aby odblokować cały folder np. Allow: /images.
Testowanie
Edytować reguły i sprawdzać ich poprawność można w Testerze pliku robots.txt znajdującym się w zakładce „Indeksowanie w Search Console”.
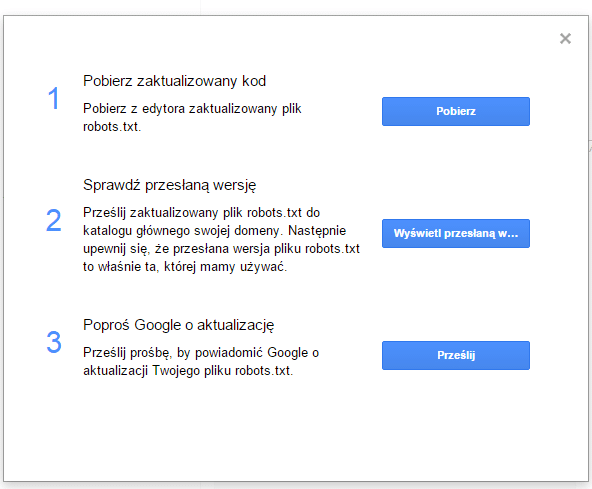
Po naniesieniu zmian należy je zapisać w pliku robots.txt na serwerze, a następnie zgłosić nową wersję pliku w Search Console. W Testerze pliku klikamy „Prześlij”, a następnie wybieramy opcję trzecią – „Poproś Google o aktualizację”.
Po kilkunastu sekundach i odświeżeniu strony aktualna zawartość pliku powinna pojawić się w oknie testera.
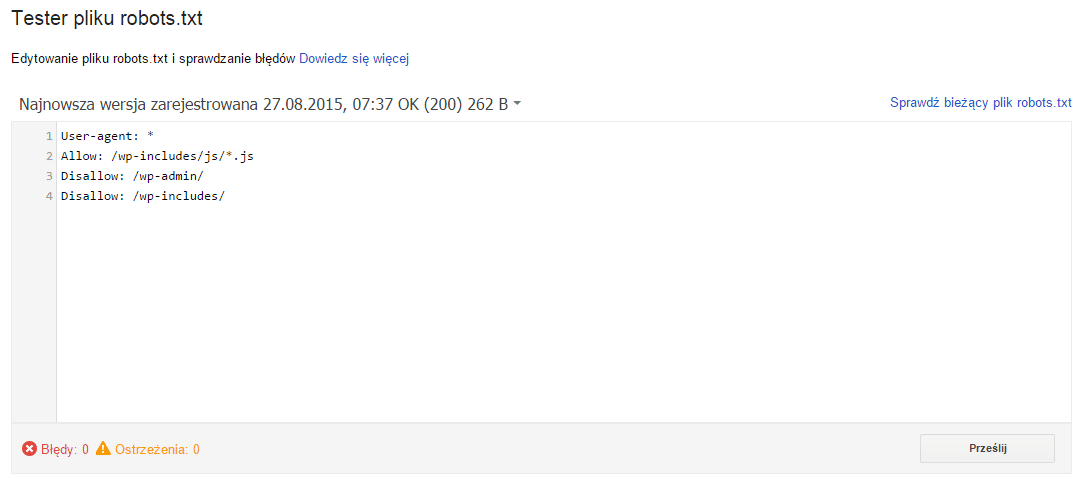
Poprzednie wersje pliku robots można podejrzeć klikając na odnośnik „Najnowsza wersja zarejestrowana (…)”.
Podsumowanie
Zazwyczaj, żeby naprawić wszystkie błędy związane z dostępem robota do zasobów wystarczy kilka chwil. Odpowiednie reguły w pliku robots.txt pozwolą na poprawną interakcję strony, co może mieć również wpływ na pozycje w wynikach wyszukiwania.

Wypełnij formularz
Przygotujemy dla Ciebie bezpłatną wycenę!
Dodatkowo otrzymasz bezpłatnie dostęp do kursów z marketingu internetowego.










