
Co to są boty internetowe? Jak działają i do czego służą? 8 faktów, które musi znać każdy właściciel strony www


W ostatnich trzydziestu latach sposób, w jaki szukamy informacji, diametralnie się zmienił. Dla naszych przodków głównym źródłem informacji były książki, gazety oraz plotki. Trochę później prym wiodło radio i telewizja, a obecnie najważniejszym medium jest internet. Mimo że powstał on w 1969 roku, a do Polski dotarł w 1991 roku, to jego znaczenie jako źródła informacji zaczęło nabierać rozpędu wraz z rozwojem wyszukiwarki Google oraz produktów jej rywali. Możliwość niemal natychmiastowego otrzymania odpowiedzi na dowolne pytanie była niewyobrażalna na początku lat 90. Dziś jeżeli czegoś nie wiemy, wpisujemy pytanie w Google: „Co to jest SEO?”, „Jak uruchomić kampanię Google Ads?”, „Czym jest spowodowany błąd 500 na stronie www?” i w ułamku sekundy otrzymujemy setki wyników, które wyjaśniają nam skrót SEO, informują, jak krok po kroku uruchomić kampanię Google Ads, czy informują, co może powodować błąd 500 na stronie internetowej i jak go naprawić. Mało kto zastanawia się, skąd Google zna te odpowiedzi. Jak to możliwe, że na pytanie, na które nie potrafił odpowiedzieć nikt z naszych znajomych, w ułamku sekundy otrzymaliśmy kompleksową odpowiedź. Wszystko to zawdzięczamy robotom Google i nie mam tu na myśli maszyn pokroju Terminatora, WALL-E czy R2D2.
Czym są boty internetowe?
Roboty zwane również botami internetowymi czy web crawlerami są programami, których zadaniem jest przeglądanie internetu i wykonywanie zaprogramowanych, powtarzalnych zadań. Powstały one w celu wyręczenia człowieka w wykonywaniu żmudnej i monotonnej pracy, w której sprawdzają się znacznie lepiej niż my. To właśnie m.in. dzięki robotom wyszukiwarek Google natychmiast jest w stanie odpowiedzieć na niemal każde pytanie. Różnego rodzaju boty są tak efektywne, że nikogo nie powinien dziwić fakt, że obecnie większość ruchu w internecie generują nie ludzie, a właśnie roboty internetowe (źródło: https://www.helpnetsecurity.com/2021/09/07/bad-bots-internet-traffic/).
Co to jest Googlebot i jak działa?
Googlebot, tak jak podobne mu roboty, jest programem, którego celem jest skanowanie stron internetowych, czyli crawlowanie. Googlebot naśladuje zachowanie człowieka i przeglądając witryny, „klika” w linki, które znajdzie. W ten sposób trafia na całkiem nowe podstrony lub na podstrony, które analizował jakiś czas temu. Dzięki pracy robotów internetowych Google nowe podstrony są dodawane do indeksu wyszukiwarki, a zawartość przeskanowanych wcześniej podstron jest aktualizowana do obecnego stanu.
Mówiąc o Googlebocie, musimy wyodrębnić kilka jego wersji, które specjalizują się w crawlowaniu określonego rodzaju treści.
Rodzaje Googlebotów
Zgodnie z informacjami udostępnionymi przez Google, Gigant z Mountain View posługuje się 18 różnymi robotami (https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=pl#adsbot). Część z nich jest używana przez wyszukiwarkę Google do indeksowania i odświeżania zaindeksowanych stron, a część wykorzystują inne produkty i usługi amerykańskiej firmy. Każdy z nich jest wyspecjalizowany w indeksowaniu różnych rodzajów typów treści, co robią w różnych celach. Jedne Googleboty naśladują użytkowników komputerów, inne smartfonów, jedne skanują tylko pliki graficzne, inne wyłącznie filmy wideo itd. Poniżej znajdują się najważniejsze rodzaje Googlebotów, które odwiedzają strony internetowe:
- Googlebot indeksujący strony na smartfony – naśladuje użytkowników smartfonów i urządzeń mobilnych, indeksuje strony internetowe,
- komputerowy Googlebot – naśladuje użytkowników komputerów stacjonarnych, indeksuje strony internetowe,
- Googlebot Image – indeksuje obrazki, zdjęcia i grafiki do Google Grafika,
- Googlebot News – indeksuje wiadomości,
- Googlebot Video – indeksuje materiały wideo,
- AdsBot – odpowiada za sprawdzanie treści reklam na stronach internetowych wyświetlanych na komputerach.

W jaki sposób boty Google indeksują strony internetowe?
Roboty wyszukiwarek skanują treści zawarte na stronach www, podobnie jak przegląda je człowiek. Odwiedzają witrynę, sprawdzają jej zawartość, a następnie przechodzą po linkach wewnętrznych na kolejne podstrony. Googleboty nie oglądają stron w takiej formie jak my. Do sprawnego poruszania się po adresach URL nie potrzebują pięknych stron z płynnymi animacjami i zaawansowanymi skryptami odpowiedzialnymi za zwiększenie użyteczności. Roboty czytają kod źródłowy strony, który dla przeciętnego użytkownika internetu jest niezrozumiały. Sam kod HTML wczytuje się znacznie szybciej, dzięki czemu robot wyszukiwarki może w krótkim czasie zapoznać się z treścią wielu stron. Znajdują się w nim różnego rodzaju znaczniki, które informują nasze przeglądarki o tym, jak formatować treść i poszczególne elementy witryny, a także nadają różne funkcje poszczególnym znacznikom. Przykładowo linki, po których boty Google, Bing i innych wyszukiwarek przechodzą na kolejne podstrony, oznaczone są w poniższy sposób:
<a href=”https://domena.pl/adres-podstrony„>Anchor</a>
W przeglądarce użytkownikowi wyświetli się wyłącznie napis Anchor, który będzie elementem klikalnym kierującym na inny adres. Robot wyszukiwarki rozpozna znacznik, jego parametry oraz anchor, a wszystko to będzie miało dla niego znaczenie, jeśli chodzi o pozycjonowanie adresu. Ponadto roboty wyszukiwarek czytają również metatagi znajdujące się w sekcji <head>, które nie są wyświetlane na stronie i w większości nie są wyświetlane użytkownikom. Wyjątkiem jest znacznik <title>, czyli tytuł, który przeważnie wyświetla się w zakładce przeglądarki.
Googleboty mogą crawlować strony internetowe na dwa sposoby:
- fresh crawl – dotyczy to stron, które są często aktualizowane – roboty wyszukiwarek odwiedzają je w celu sprawdzenia, co zmieniło się od ostatniej wizyty, i zaktualizowania informacji już przechowywanych w indeksie Google,
- deep crawl – robot odwiedza witrynę i korzystając z linków znajdujących się na niej, porusza się po serwisie, indeksując nowe podstrony i aktualizując treść wcześniej zaindeksowanych adresów URL.
Oprócz poruszania się po stronie tak jak ludzie Googleboty korzystają również z mapy witryny zapisanej w formacie XML, która pomaga im w poruszaniu się po stronie.
Mapa witryny
Mapa strony nie jest elementem niezbędnym robotom Google do indeksowania treści, szczególnie jeśli witryna jest zaindeksowana i właściciel nie rozwija jej intensywnie przez dodawanie nowych podstron. W przypadku gdy tworzymy nową stronę, zmieniamy silnik witryny na inny, mocno modyfikujemy strukturę serwisu lub bardzo często dodajemy nowe podstrony, np. publikujemy wiele artykułów, mapa witryny w formacie XML może w dużym stopniu pomóc botom Google w szybszym zaindeksowaniu nowych adresów URL.
Najczęściej spotkamy mapy strony zapisane w formacie XML, ale gigant z Mountain View obsługuje również inne ich formaty:
- XML,
- RSS, mRSS i Atom 1.0,
- tekstowy.
W przypadku map XML, powinny mieć one postać zgodną z poniższym przykładem:
<?xml version=”1.0″ encoding=”UTF-8″?>
<urlset xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″>
<url>
<loc>https://www.domena.pl/adres-strony.html</loc>
<lastmod>2022-06-16</lastmod>
</url>
</urlset>
Pierwsze dwie linie kodu definiują typ pliku, kodowanie i standard. W kolejnych czterech liniach podawane są adresy należące do witryny. Tag <url> zawiera dane związane z pojedynczym adresem URL. Znacznik <loc> zawiera pełen adres podstrony wraz z protokołem i domeną, a tag <lastmod> informuje o ostatniej aktualizacji adresu. W niektórych mapach witryn możemy się spotkać jeszcze ze znacznikami:
- <priority>, który oznacza priorytet – im ma on wyższą wartość (bliższą 1), tym adres jest ważniejszy,
- <changefreq>, który informuje, jak często adres jest aktualizowany.
Oba powyższe znaczniki są obecnie ignorowane przez Google, ale mogą znajdować się w mapach witryn.
Mapy witryn można generować ręcznie, ale znacznie lepiej wykorzystać do tego dedykowane wtyczki czy oprogramowanie. Przykładowo właściciele stron internetowych opartych na systemie WordPress mogą zainstalować wtyczkę Yoast SEO (https://pl.wordpress.org/plugins/wordpress-seo/) i za jej pomocą wygenerować mapę strony. W przypadku gdy CMS nie posiada wtyczek generujących mapę strony, można do tego wykorzystać narzędzia takie jak np. https://www.xml-sitemaps.com/, który w ciągu kilku sekund przygotuje za nas cały plik XML.
W przypadku tworzenia mapy w postaci tekstowej wystarczy w pliku txt umieścić listę adresów URL np.:
https://www.domena.pl/adres-strony1.html
https://www.domena.pl/adres-strony2.html
Z ważnych rzeczy, o których należy pamiętać w przypadku tworzenia map witryny, jest ograniczenie jej rozmiaru. Mapa może mieć maksymalnie 50 MB i jeżeli przekracza ten rozmiar, należy ją podzielić na kilka mniejszych plików. Problem ten będzie dotyczył wyłącznie największych serwisów z setkami tysięcy adresów.
Linki
W powyższej części napisałem, że roboty wyszukiwarek sprawdzając zawartość witryny, korzystają z linków na niej umieszczonych. Odnośniki na stronach mogą mieć dodatkowe atrybuty, które wpływają na to, jak boty je traktują. Niektóre z parametrów nie mają wpływu na poruszanie się po linkach, a inne są informacją dla robotów Google, by po konkretnym odnośniku nie podążały.
Najczęściej spotykanym atrybutem, który informuje roboty wyszukiwarek, że nie mają podążać za linkiem, jest rel=”nofollow”. Najważniejsze znaczenie tego atrybutu to blokowanie przekazywania tzw. link juice strony linkującej do podlinkowanego adresu. Z reguły takim atrybutem oznacza się odnośniki wychodzące do innych domen, np. link ze stopki do strony internetowej twórcy serwisu, ale stosuje się go również w linkach wewnętrznych prowadzących do stron o niskiej wartości dla robotów Google. Takimi podstronami mogą być np.:
- podstrona koszyka,
- podstrona logowania/rejestracji,
- dodanie produktu do obserwowanych,
- różne typy sortowania produktów,
- strony w budowie,
- strony z duplikatami treści itp.
Link z atrybutem informującym, że roboty nie mają podążać za odnośnikiem, ma poniższą postać:
<a href=”/adres-strony1.html” rel=”nofollow”>Strona 1</a>
Teoretycznie roboty Google widząc powyższy link, nie powinny odwiedzać strony /adres-strony1.html. W praktyce jednak wygląda to inaczej i boty często ignorują ten parametr, jeśli chodzi o indeksowanie treści. W przypadku gdyby jednak taki parametr znajdował się na linkach do ważnych podstron, takich jak strona główna, strony kategorii, produktów itp., należy go usunąć.
Google Search Console (GSC)
Jednym z najważniejszych narzędzi, które pomaga zrozumieć, jak działają boty Google, oraz sprawdzić statystyki indeksowania, jest Google Search Console, czyli GSC. Narzędzie to jest darmowe i każdy właściciel strony powinien je zainstalować na swojej witrynie. Instrukcję instalacji Google Search Console oraz możliwości narzędzia zostały opisane w poradniku GSC opublikowanym na naszym blogu (Google Search Console).
Za pomocą tego narzędzia możemy przede wszystkim zgłosić naszą mapę witryny, która powinna przyspieszyć indeksowanie strony. Po jej wysłaniu możemy też zweryfikować, czy mapa nie zawiera błędów, i sprawdzić statystyki z nią związane, jak np. liczbę adresów, które zawiera, datę przesłania i datę ostatniego odczytania.
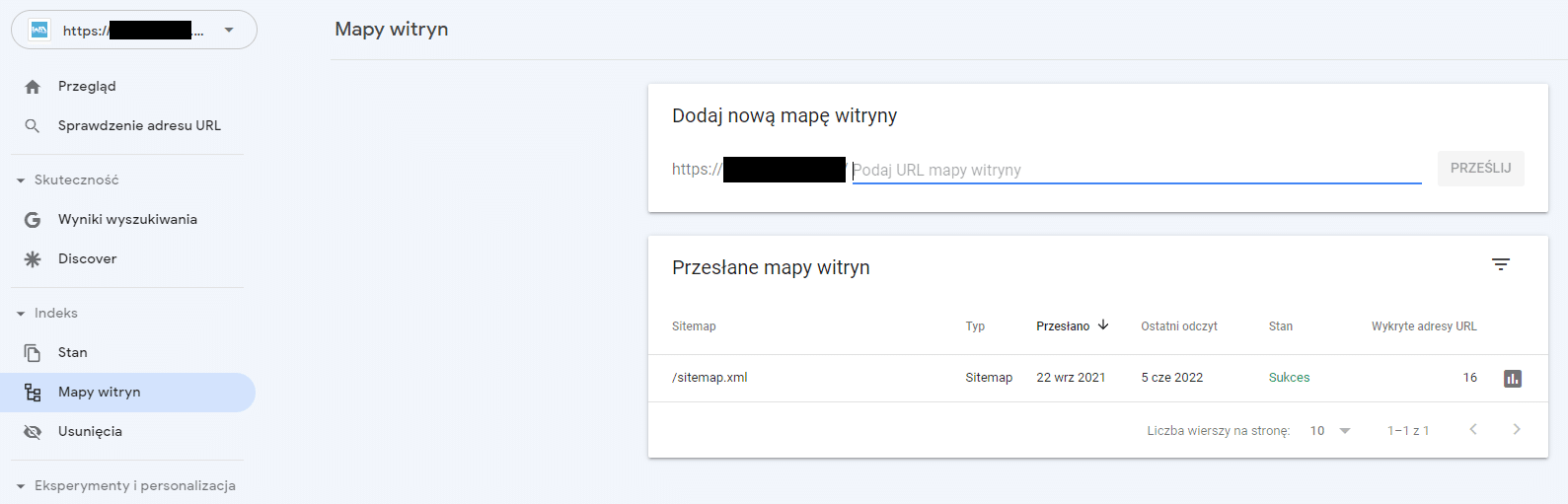
Ponadto GSC bardzo przydaje się przy zgłaszaniu do zaindeksowania pojedynczych podstron. Jeśli na stronie zostanie dodany nowy artykuł, kategoria, produkt, strona informacyjna lub jakąś podstronę zaktualizujemy, wystarczy zgłosić taki adres URL za pomocą opcji „Sprawdzenie adresu URL”, a w ciągu ok. 48 godzin zgłoszona podstrona powinna zostać przeindeksowana. Z opcji tej bardzo często korzystam w swojej pracy, zgłaszając do przeindeksowania adresy, na których zoptymalizowałem znaczniki sekcji head i nagłówki, dodałem treści czy wprowadziłem inne zmiany związane z pozycjonowaniem stron internetowych klientów.
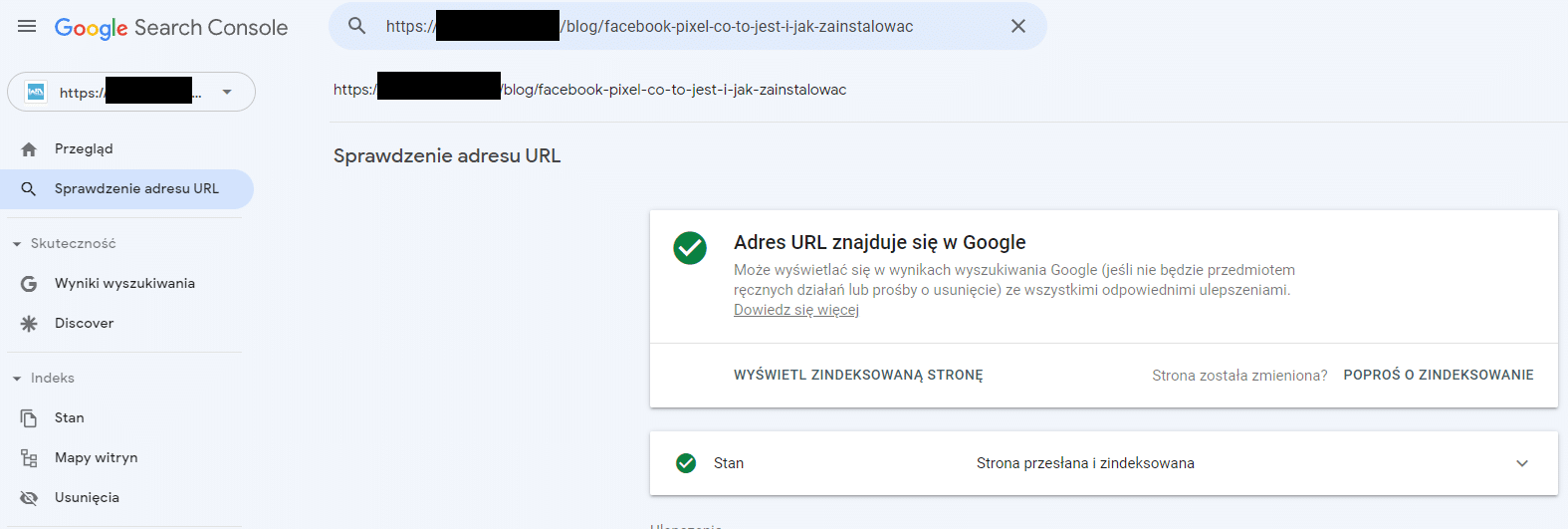
Korzystając z Google Search Console, możemy również sprawdzić statystyki indeksowania, które pokazują, ile żądań wysłały roboty wyszukiwarek, jaki był rozmiar pobranych zasobów, średni czas reakcji, jakie typy plików były pobierane, jakie nagłówki odpowiedzi zwracały skanowane adresy, jakie typy botów poruszały się po serwisie i w jakim celu Googlebot odwiedził witrynę.
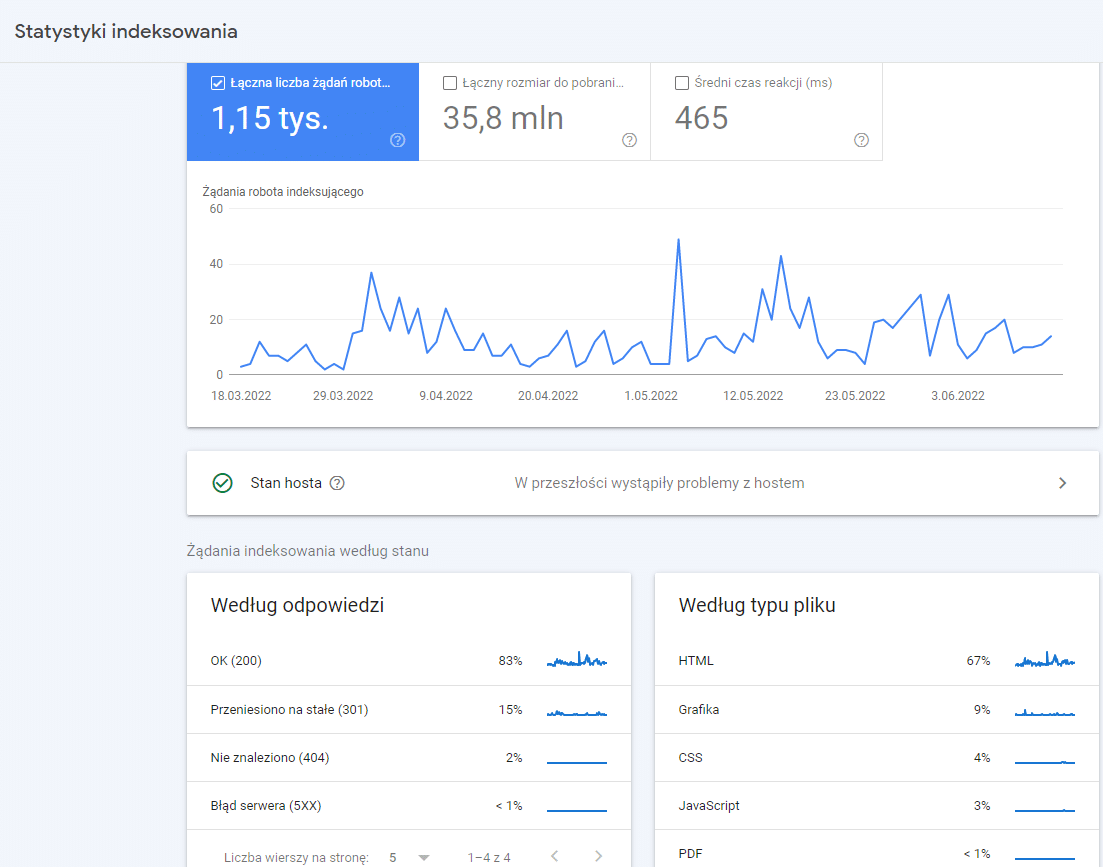
Innym przydatnym ustawieniem w GSC, które dotyczy indeksowania strony, jest „Szybkość indeksowania” (https://www.google.com/webmasters/tools/settings). Z reguły Google automatycznie określa optymalną szybkość indeksowania strony. Czasami możemy jednak chcieć zmienić te ustawienia. Wtedy za pomocą tego ustawienia możemy ręcznie zdefiniować, czy szybkość indeksowania ma być niska czy wysoka. W przypadku nowych stron i serwisów, gdzie dodawanych jest dużo nowych treści, warto przesunąć suwak na maksymalną szybkość. Jeśli witryna znajduje się na serwerze o słabych parametrach i częste wizyty botów Google spowalniają działanie strony, a nie ma potrzeby jej częstego indeksowania, suwak można przesunąć na minimalną wartość.
Dlaczego roboty Google nie indeksują strony www?
Opisany powyżej proces indeksacji wydaje się prosty i teoretycznie po stworzeniu nowej strony www, stosując się do opisanych wskazówek, powinniśmy być w stanie „wymusić” zaindeksowanie jej treści w ciągu kilku dni. Co jednak, gdy mimo wykonania powyższych instrukcji strony czy pojedynczych podstron nie ma w indeksie przez tydzień czy nawet kilka miesięcy? Powodów takiego stanu może być kilka, jednak zanim zaczniemy panikować, najpierw upewnijmy się, czy rzeczywiście naszej strony nie ma w indeksie, bo może po prostu źle jej szukamy.
Najlepszą metodą na sprawdzenie, czy nasza domena jest w indeksie, jest wykorzystanie operatora site w polu wyszukiwania. Wpisujemy komendę:
site:domena.pl
np.
site:grupatense.pl
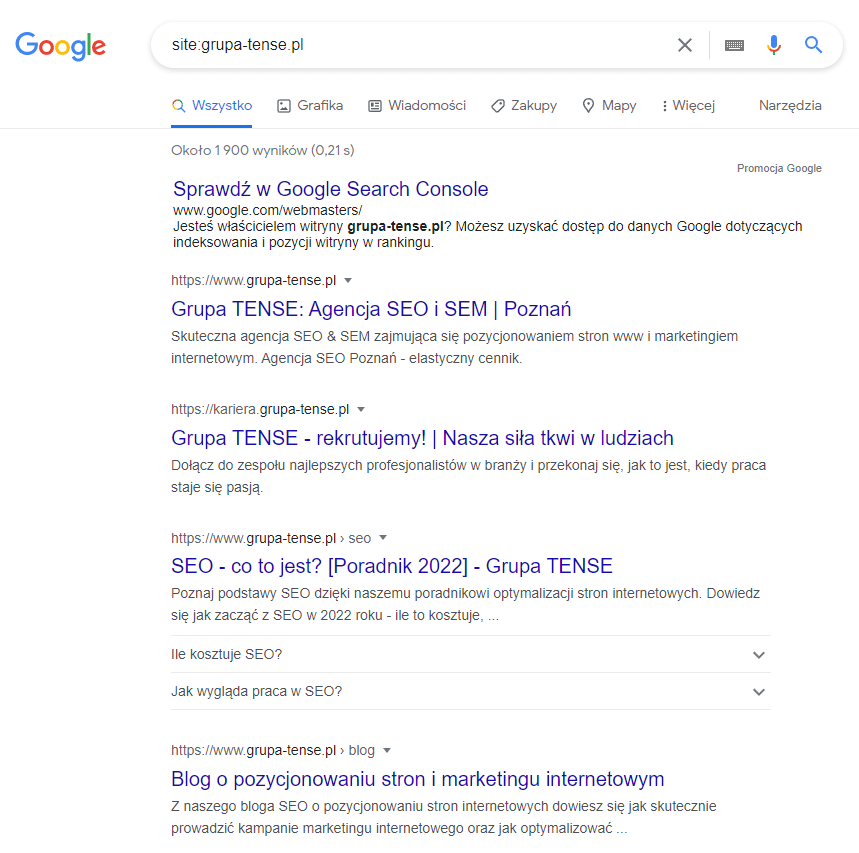
W odpowiedzi otrzymamy listę wszystkich zaindeksowanych podstron znajdujących się w danej domenie. Jeżeli wynik nie jest pusty, oznacza to, że witryna jest indeksowana.
Kolejnym krokiem jest sprawdzenie, czy w indeksie znajduje się konkretny adres URL. Przy małych witrynach można po prostu przejrzeć adresy, które pojawiły się w wynikach. W dużych serwisach najlepiej wykorzystać inny operator – cache.
Stosujemy go podobnie jak poprzedni, wpisując w polu zapytania operator i po dwukropku podając adres szukanej podstrony:
cache:http://domena.pl/adres-strony1.html
np.
cache:https://www.grupatense.pl/seo/
Jeżeli strona znajduje się w indeksie, otrzymamy wgląd w zaindeksowaną wersję wraz z informacjami, z jakiego dnia pochodzi wyświetlona kopia, którą wykonało Google.

W przypadku gdy naszej strony nie ma w indeksie Google, w odpowiedzi otrzymamy poniższy komunikat o błędzie 404.
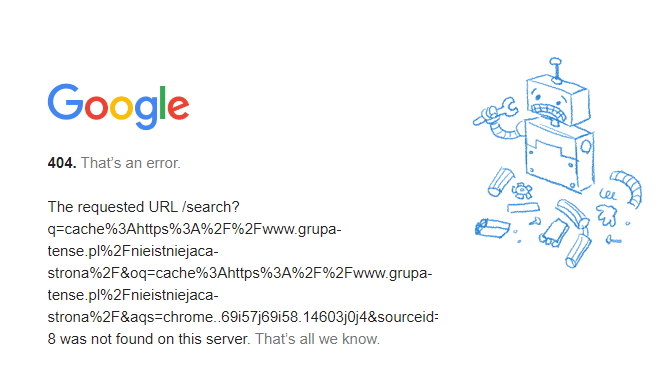
Co zrobić w takim przypadku? Przede wszystkim nie panikować. Przyczyny braku strony w indeksie możemy spróbować zweryfikować w GSC podczas korzystania z funkcji „Sprawdzania adresu URL”, ale nie wszystkie problemy zostaną tam pokazane.
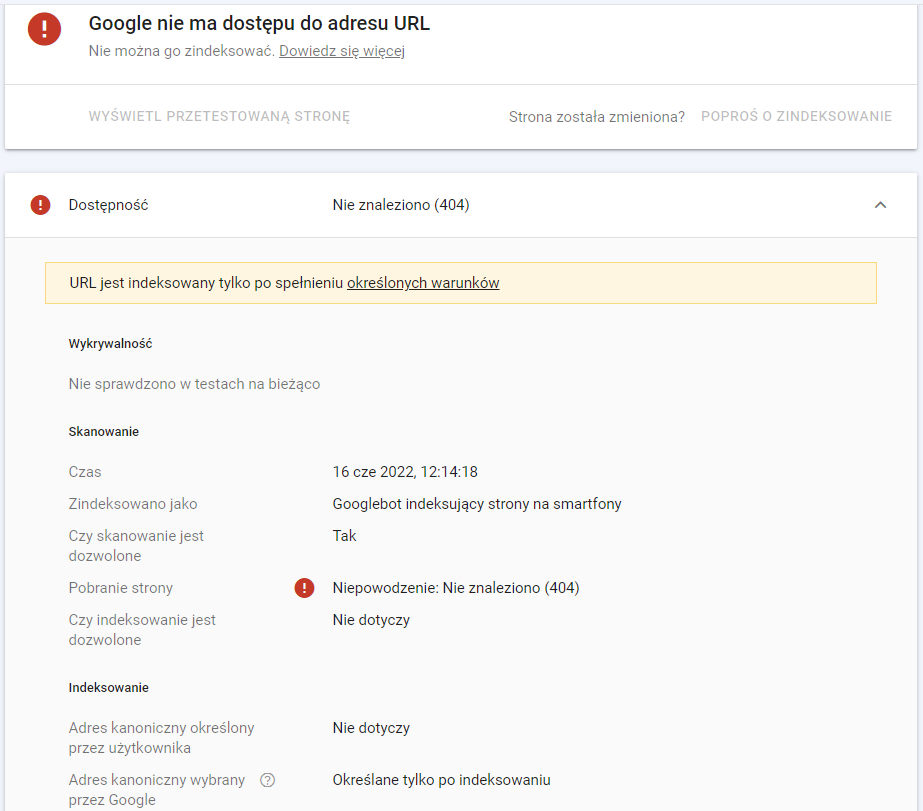
Źródło: Google Search Console
Najczęściej przyczyną braku indeksowania adresu są blokady indeksowania, nieprawidłowo zaimplementowany znacznik canonical lub odpowiedzi nagłówków HTTP inne niż 200. Jak sprawdzić i rozwiązać te problemy? Już wszystko wyjaśniam.
Plik robots.txt
Plik robots.txt znajduje się zawsze w głównym katalogu ze stroną i powinien być dostępny pod adresem:
http://domena.pl/robots.txt
np.
https://www.grupatense.pl/robots.txt
Plik ten zawiera instrukcje dla robotów, które m.in. informują je, czy indeksowanie danego adresu lub danej ścieżki jest dozwolone czy zabronione. Instrukcje Disallow blokują indeksowanie, a instrukcje Allow dopuszczają indeksowanie danych zasobów.
W celu weryfikacji czy nasz plik robots.txt blokuje indeksowanie danego adresu najlepiej otworzyć w GSC Tester robots.txt (https://www.google.com/webmasters/tools/robots-testing-tool), za pomocą którego szybko zweryfikujemy, czy adres jest zablokowany za pomocą tej metody.
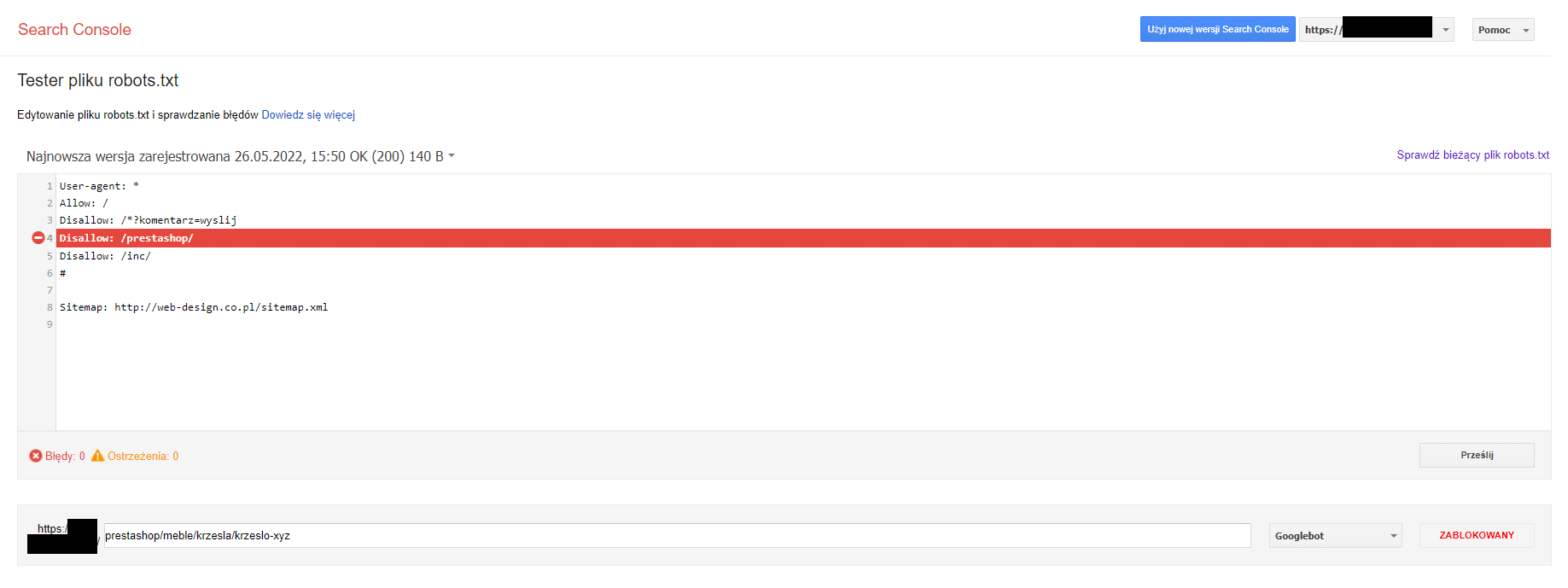
Jeżeli zobaczymy informację o blokadzie jak na powyższym zrzucie, to znaczy, że nasz adres nie jest indeksowany, ponieważ instrukcje w pliku robots.txt zabraniają Googlebotom indeksowania treści. W takim przypadku należy zmodyfikować instrukcje w pliku, by pozwalały na indeksowanie danej ścieżki czy adresu.
W naszym przypadku wystarczy dodać w pliku poniższą instrukcję:
Allow: /prestashop/meble/krzesla/krzeslo-xyz
W przypadku gdybyśmy mieli wiele adresów, które są blokowane w danej ścieżce, można również odblokować cały katalog, zmieniając dyrektywę:
Disallow: /katalog/
na:
Allow: /katalog/.
Dla powyższego przykładu należałoby zmienić:
Disallow: /prestashop/
na:
Allow: /prestashop/
Efektem tej zmiany będzie zezwolenie na indeksację dozwolenie indeksacji wszystkich adresów, które w ścieżce mają dany katalog (w tym przypadku /prestashop/).
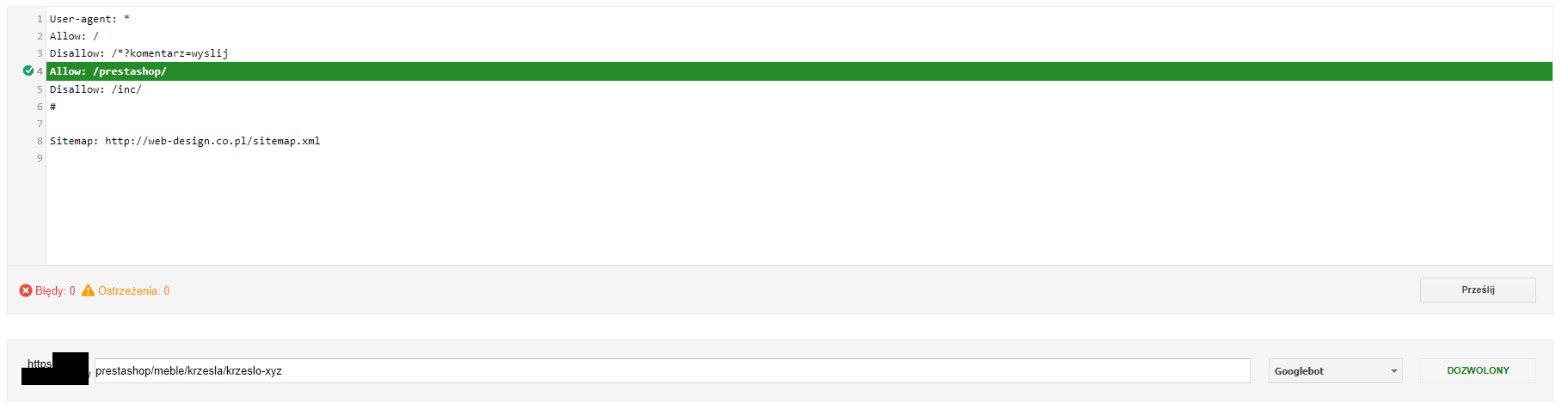
Należy pamiętać o tym, by zawartość pliku robots.txt zmienić na serwerze, a nie w GSC, które służy tylko do jego testowania i zmian wprowadzanych za jego pomocą nie zapisuje na serwerze.
Znacznik meta-robots
Drugą często spotykaną przyczyną nie indeksowania treści jest blokada za pomocą meta tagu robots. Znacznik ten znajduje się w sekcji head witryny i podobnie jak plik robots.txt zawiera instrukcje informujące roboty, czy mogą indeksować dany adres URL. Znacznik może mieć dwie wartości dotyczące indeksowania:
- index – zezwala na indeksowanie zawartości danego adresu URL,
- noindex – nie pozwala na indeksowanie zawartości danej podstrony.
Cały znacznik najczęściej wygląda następująco:
<meta name=”robots” content=”index, follow” />
<meta name=”robots” content=”noindex, follow” />
W przypadku gdy na naszej stronie, której nie ma w indeksie, znajduje się ta druga wersja znacznika robots z noindex w atrybucie content, adres nie zostanie zaindeksowany. Zawartość znacznika robots możemy sprawdzić ręcznie, wyświetlając kod źródłowy strony, posłużyć się narzędziem do crawlowania lub skorzystać z darmowych narzędzi do weryfikacji tego znacznika, takich jak np. https://www.seoreviewtools.com/bulk-meta-robots-checker/ lub różnego rodzaju wtyczki do przeglądarek.
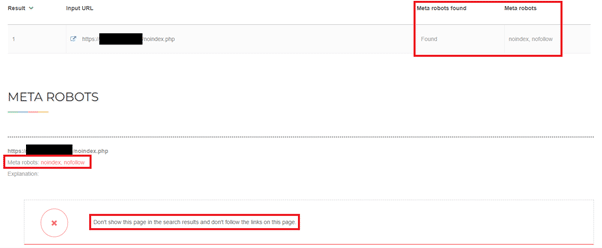
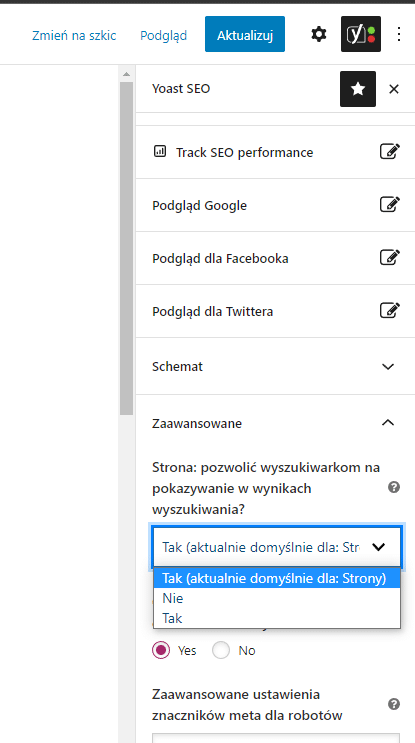
Blokadę indeksowania należy zdjąć, zmieniając wartość z noindex na index. W części CMS-ów, jak np. WordPress, będzie to możliwe do wykonania z poziomu panelu administracyjnego (czasami konieczna będzie instalacja dodatkowych wtyczek do zarządzania ustawieniami), a w części konieczna będzie przynajmniej podstawowa znajomość HTML i ręczna edycja szablonu strony z sekcją head.
Znacznik canonical
Innym znacznikiem, który również może uniemożliwiać indeksowanie adresu URL, jest znacznik canonical. Wykorzystuje się go do wskazywania robotom wyszukiwarek kanonicznego adresu. Często można spotkać strony, które mają znacznik canonical wskazujący ich własny adres, co nie wpływa na indeksację. Znacznik canonical jest bardzo przydatny, jeśli chcemy uniknąć indeksowania duplikatów wewnętrznych na serwisie, np. adresów z parametrami, których moc SEO dzięki odpowiedniemu znacznikowi canonical może być kumulowana na adresie bez parametru. Problem pojawia się, w przypadku gdy znacznik canonical na adresie, który chcemy zaindeksować, wskazuje inny adres. W takim przypadku roboty wyszukiwarek mogą nie indeksować strony. Przykładowo jeżeli chcemy zaindeksować adres http://domena.pl/nowa-strona.html, a w sekcji head tej podstrony znajduje się poniższy znacznik canonical:
<link rel=”canonical” href=”http://domena.pl/stara-strona.html” />
to adres nowej strony nie będzie indeksowany, ponieważ roboty Google otrzymują informację, że kanonicznym adresem jest adres http://domena.pl/stara-strona.html.
Weryfikacji znacznika canonical możemy dokonać ręcznie, sprawdzając kod źródłowy witryny, skorzystać z jednej z wielu wtyczek lub posłużyć się narzędziem online do takiej weryfikacji np. https://www.seoreviewtools.com/canonical-url-location-checker/.
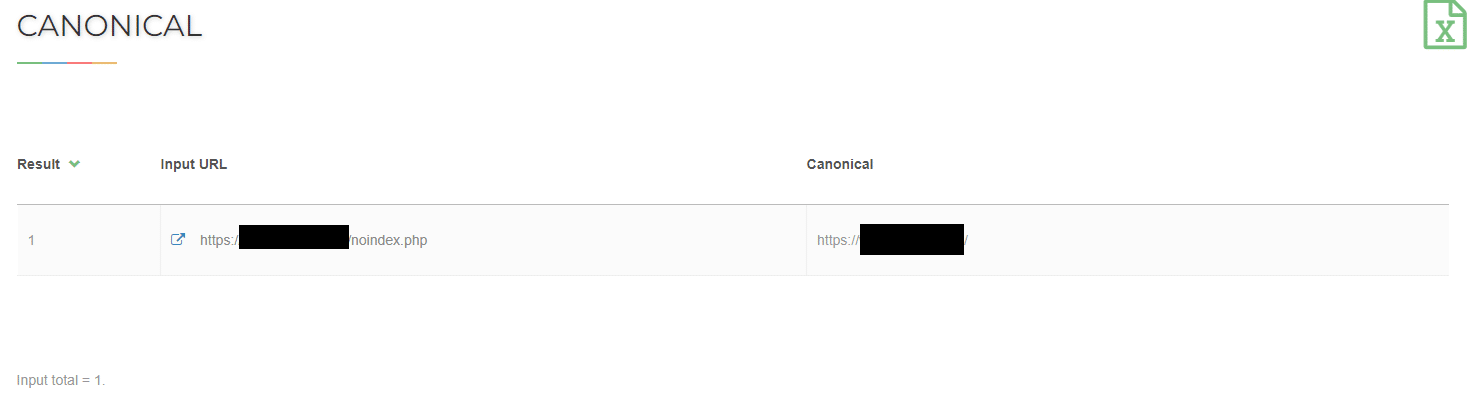
W przypadku błędnego znacznika canonical należy poprawić go w CMS lub w szablonie strony. Podobnie jak w przypadku znacznika robots część systemów do zarządzania treścią posiada ustawienia do zarządzania znacznikami canonical lub ma możliwość instalacji wtyczki, która będzie dawała taką funkcjonalność.
Błąd 404 i inne błędy 4xx
Kolejnym problemem uniemożliwiającym indeksowanie adresu są błędy 4xx, z czego najczęściej spotykanym jest błąd 404 Not found oznaczający, że adres strony nie został znaleziony. Najczęściej taki błąd pojawia się, jeśli w adresie URL znajduje się błąd, np. literówka. Warto wtedy zweryfikować, czy prawidłowo wpisaliśmy adres naszej strony, czy odnośniki, które do niej prowadzą, nie zawierają błędów, czy adres podany w mapie witryny jest dokładnie taki sam jak nasza strona.
W przypadku gdy mamy pewność, że z adresem wszystko jest ok i strona działa prawidłowo, w pomoc warto zaangażować programistę. Sprawdzi on, co jest przyczyną nagłówka HTTP odpowiedzi zwracającego kod 4xx, i poprawi go na kod 200 oznaczający, że ze stroną wszystko jest OK i może być indeksowana.
To, czy nasza strona zwraca błąd 404, możemy sprawdzić za pomocą wielu narzędzi, takich jak np. https://httpstatus.io/.
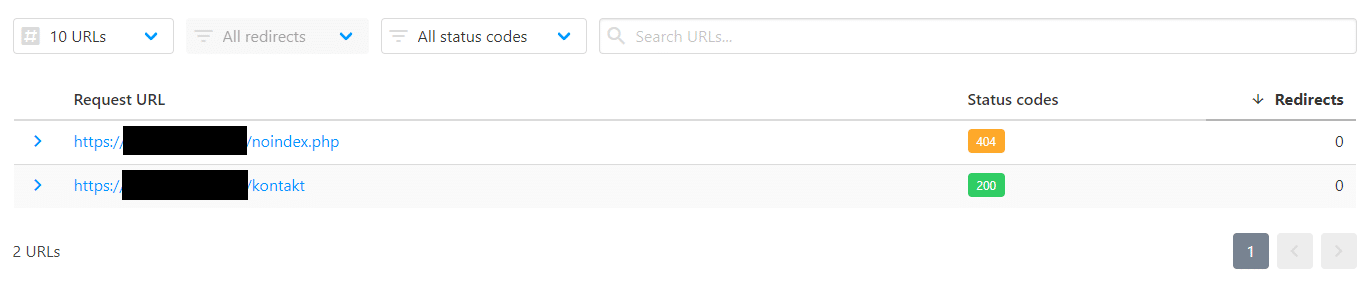
Błąd 500 i inne błędy 5xx
Rzadziej spotykanym problemem, który uniemożliwia indeksowanie treści, są błędy 5xx oznaczające problem po stronie serwera. Mogą one oznaczać problem występujący po stronie hostingu, ale również być wywołane np. nieprawidłową konfiguracją pliku .htaccess. Błędy tego typu możemy wykryć podobnie jak błędy 4xx. Jeżeli narzędzie do testowania witryny wykaże błąd typu 5xx, najlepszym rozwiązaniem będzie zgłoszenie problemu programiście, który powinien zidentyfikować, co powoduje błąd, naprawić go lub skontaktować się z administratorami hostingu, jeśli problem występuje z ich winy.
Inne przyczyny
Inną przyczyną problemów z indeksowaniem zawartości strony może być technologia zastosowana do jej stworzenia. Roboty Google są cały czas rozwijane i z każdym rokiem lepiej radzą sobie z indeksowaniem treści, ale nadal niektóre technologie uniemożliwiają indeksowanie zawartości witryny lub mają duży wpływ na niską szybkość takiego indeksowania. Zlecając stworzenie nowej strony, warto mieć to na uwadze i wybierać technologie, z których indeksacją roboty Google radzą sobie dobrze. Należy unikać wszystkich technologii, w których renderowanie strony następuje po stronie użytkownika lub z wykorzystaniem JavaScriptu do wygenerowania kluczowych elementów, takich jak nawigacja, nagłówki, treści itp. Z indeksowaniem takich witryn nadal występują poważne problemy.
Jakie boty odwiedzają strony?
Po stronach internetowych poruszają się różne rodzaje botów. Część z nich, tak jak Googlebot i roboty innych wyszukiwarek, jest przydatna, ale wiele innych z różnych powodów jest niepożądana.
Pożądane
Do „dobrych” botów, które odwiedzają strony internetowe, zaliczyć należy roboty wyszukiwarek takich jak Google, Bing, Yahoo, DuckDuckGo i wielu innych. Ich wizyty, tak jak opisałem to w tym artykule, wiążą się z indeksowaniem stron internetowych, dzięki czemu później użytkownicy korzystający z tych wyszukiwarek mogą w nich znaleźć naszą stronę.
Drugim rodzajem robotów, które może gościć nasza witryna, są różnego rodzaju crawlery firm analizujących witrynę. Mogą one badać naszą stronę pod kątem linków wychodzących i przychodzących, występowania słów kluczowych i innych parametrów ważnych w SEO. Przykładami takich firm posiadających własne roboty są np. Ahrefs, Majestic, SEMRush.
Ostatnim rodzajem botów, które mogą odwiedzać nasz serwis, są roboty dostarczające zawartość strony do aplikacji mobilnych i webowych, czyli tzw. feed fetchers. Przykładami takich botów mogą być roboty Androida, Apple czy Facebooka.
Niepożądane
Oprócz botów, które chętnie gościmy na naszej witrynie, ponieważ mogą dawać nam jakieś korzyści czy to w postaci widoczności w wynikach wyszukiwania, czy w postaci informacji na temat braków w optymalizacji, naszą stronę www mogą odwiedzać niepożądane roboty.
Tego typu „złe” boty z reguły próbują się podszywać pod użytkowników poprzez sposób przedstawiania się z wykorzystaniem zmienionego nagłówka user-agent i obsługi rozwiązań, z których roboty zazwyczaj nie korzystają. Takie boty mogą być wykorzystywane do ataków DDoS, które powodują przeciążenie serwera i zablokowanie strony lub usługi.
Niepożądanymi robotami są również te należące do różnego rodzaju narzędzi hakerskich. Z reguły tego typu boty skanują stronę internetową pod kątem luk, przez które haker może uzyskać do niej dostęp i przeprowadzić atak, zawirusować witrynę czy podmienić jej zawartość.
Kolejnym rodzajem niechcianych botów są spamerskie roboty, których celem jest publikacja niechcianych treści, często reklam lub linków do stron o wątpliwej jakości. Takie boty często poruszają się po stronach z formularzami – jak np. fora internetowe, blogi z opcją komentowania, ale również strony kontaktowe itp. – i za pomocą formularzy rozpowszechniają spam.
Ostatnim typem niepożądanych robotów są różnego rodzaju scrapery, które masowo pobierają treści ze strony.
Niepożądane boty powodują nie tylko zbędne obciążenie strony, ale mogą również doprowadzić do większych strat. Jeżeli zatem podczas analizy ruchu wykryjemy „złe” roboty, warto zablokować im dostęp do strony, np. za pomocą pliku .htaccess i instrukcji Deny blokującej dostęp do witryny dla wskazanych adresów IP.

Podsumowanie
Jak widać roboty wyszukiwarek, a szczególnie Googleboty, są niezwykle użytecznymi programami, bez których korzystanie z internetu w taki sposób, jak robimy to obecnie, byłoby właściwie niemożliwe. To dzięki nim wpisując zapytania w wyszukiwarkach, otrzymujemy kompleksowe odpowiedzi. To właśnie roboty odpowiadają, za to, że nasza strona znajduje się w wyszukiwarce, a jej kopia przechowywana przez wyszukiwarkę jest systematycznie aktualizowana. Jeżeli zatem posiadamy stronę internetową, warto dostosować ją, by była przyjazna dla robotów Google. W przypadku braku umiejętności pozwalających na samodzielne dostosowanie kodu strony, zachęcam do skorzystania z pomocy specjalistów z Grupy TENSE, którzy zoptymalizują witrynę do wymagań Googlebotów i pomogą ją wypozycjonować na słowa kluczowe związane z prowadzoną na serwisie działalnością.

Wypełnij formularz
Przygotujemy dla Ciebie bezpłatną wycenę!
Dodatkowo otrzymasz bezpłatnie dostęp do kursów z marketingu internetowego.
















